



Lección 18 - Habla con tu historial completo de ChatGPT


En esta lección vamos a extraer todos los chats de nuestra cuenta de ChatGPT para trabajar y conversar con ellos a través de NotebookLM.
Uno de los grandes problemas de trabajar con IA es que estamos generando una cantidad enorme de información y cada vez es más difícil encontrar algo entre los cientos de chats que tenemos con GPT.
En la Lección 5 vimos cómo establecer un sistema para categorizar chats que te recomiendo que utilices. A eso le podemos sumar el buscador de palabras clave que han añadido en la propia interfaz de ChatGPT, aunque es insuficiente si necesitamos una búsqueda más "semántica", es decir: sabemos qué queremos, pero no las palabras exactas.
En ese caso podemos echar mano de la "memoria a largo plazo" que integra ChatGPT, que va recordando trozos de información relevantes de nuestros chats, ya sea de forma automática o cosas concretas que le hemos pedido que almacene. El problema es que esa memoria es limitada. No almacena toda la información y cada cierto tiempo se llena.
Así que mientras llega la famosa AGI (Inteligencia Artificial General) o un agente que sea capaz de integrar de forma automática toda nuestra información, no nos queda otra que mantener cierto control y bucear en los datos de forma "manual".
Y eso es lo que haremos en esta lección. Obtendremos TODAS nuestras conversaciones y las usaremos como documentación en NotebookLM para trabajar y charlar con ella, algo mucho más útil que una simple búsqueda de palabras clave.
Obteniendo nuestro historial
El primer paso es entrar a ChatGPT. Pulsamos en nuestra imagen de perfil y accedemos a la configuración. Allí vamos hasta "Controles de datos" y pinchamos en "Exportar datos".
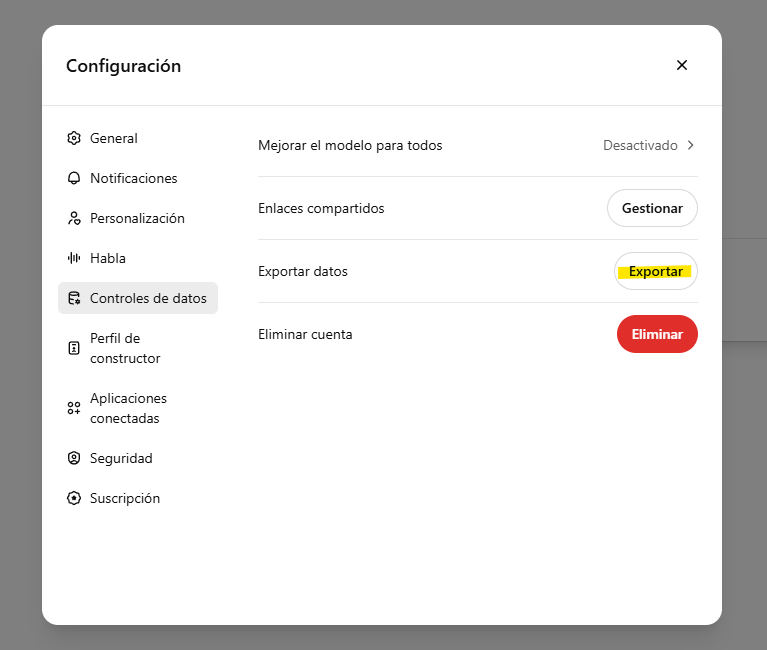
OpenAI nos mandará a los pocos minutos un correo electrónico para descargar todas las conversaciones en formato comprimido. Será un archivo con una ristra enorme de números. Esto es así para hacernos la vida más difícil.
Una vez descomprimido, la carpeta tiene la siguiente estructura:

Para esta lección nos interesa el archivo "chat.html". Lo abrimos con el navegador.
Como vemos, aparecen todas nuestras conversaciones hasta el inicio de los tiempos, bien maquetadas y separadas entre sí.
Preparando los datos para hablar con ellos
Ahora tenemos varias formas de proceder para aprovechar todos estos datos. Yo voy a usar el famoso método "compae", bautizado por un buen amigo para referirse a todas estos apaños cutres que hacemos para no complicarnos.
En este caso es tan simple como seleccionar todo el texto del archivo en el navegador (CONTROL + A), y copiarlo y pegarlo en un editor de texto .
Ojo. Si tenéis un archivo enorme no nos vale Word ni Google Docs, porque se van a bloquear. Necesitamos un programa simple, como el Bloc de Notas de Windows o mejor: Notepad ++ o Sublime Text.
Yo uso Sublime Text y os lo recomiendo encarecidamente. Allí simplemente pegamos todo el texto que hemos copiado y le damos unos segundos para que procese. Luego podemos guardarlo donde queramos como "Chats.txt". Mi texto tiene aproximadamente cinco millones y medio de caracteres en 65.000 líneas. Eso son bastantes palabras.
NotebookLM es la plataforma que usaremos para trabajar con nuestro archivo de chats. Es una herramienta genial de Google que permite chatear y trabajar con varios documentos o fuentes. Tenemos pendiente una lección para estudiar en profundidad todas sus posibilidades, pero esto cuenta como aperitivo.
Aunque NotebookLM tiene una ventana de contexto enorme (más de un millón de tokens), no le vale cualquier archivo. Mi "Chats.txt" no lo acepta, supongo que es demasiado largo. Si el tuyo se lo traga sin problema, puedes saltarte este paso. De lo contrario, podemos hacer lo siguiente.
Dividir el archivo TXT en dos partes

Hay muchas formas de dividir un archivo de texto en dos (o las que hagan falta). Podemos usar algún programa, comandos o simplemente de forma manual:
Abrimos nuevamente el archivo "Chat.txt" con Sublime Text o Notepad ++ y nos desplazamos hasta la mitad. Esto podemos hacerlo a ojímetro (con la barrita de desplazamiento) o de forma exacta, mirando las líneas que ocupa el texto en total y yendo a la mitad (en mi caso 32.500).
Ahora solo quedaría seleccionar la mitad del documento hacia abajo y cortarlo y pegarlo en otro nuevo archivo que llamaremos "Chats2.txt". El original lo guardamos como "Chats1.txt". Ya lo tenemos en dos partes.
Truco: Si el documento es enorme, como es mi caso, te puedes tirar media hora seleccionando el texto hacia abajo. Para hacerlo más fácil pulsamos CONTROL + MAYÚSCULAS + END y nos selecciona de forma automática todo el texto desde donde tengamos el cursor hasta el final del documento.
Trabajando en NotebookLM
Entramos a NotebookLM, nos registramos con nuestra cuenta de Google y creamos un nuevo cuaderno.
Nos pedirá que añadamos las fuentes de información. Como ya veremos en su momento, podemos añadir documentos de Google, vídeos de Youtube, PDFs, etc. En este caso solamente añadimos nuestros documentos de texto “Chats1.txt” y “Chats2.txt” con el historial de conversaciones de ChatGPT.

Nos genera la libreta y nos hace una breve sinopsis del documento. Así se ve la interfaz general de NotebookLM una vez creada la libreta.

A mano izquierda tenemos los archivos que hemos subido, en el centro el chat para hablar con esos documentos y a la derecha el panel para generar y guardar notas.
Yo he empezado preguntándole qué sabe de Artificialmente, para comprobar qué información podía recuperar de todas mis conversaciones con ChatGPT. Como vemos, ha sacado los trapos sucios de que lo utilicé para generar el logotipo (describiendo las indicaciones) y otras tantas cosas.
Lo interesante es que genera citas del lugar del texto de donde saca la información, por si quieres comprobarlo en la conversación original.
Ahora le pregunto acerca de una conversación muy antigua donde pedía que ChatGPT generase diapositivas para PowerPoint.

En un momento nos devuelve lo que hablamos y hasta me recupera el código en Visual Basic que generó. Muy chulo.
También podemos probar si alucina con alguna pregunta de este estilo:
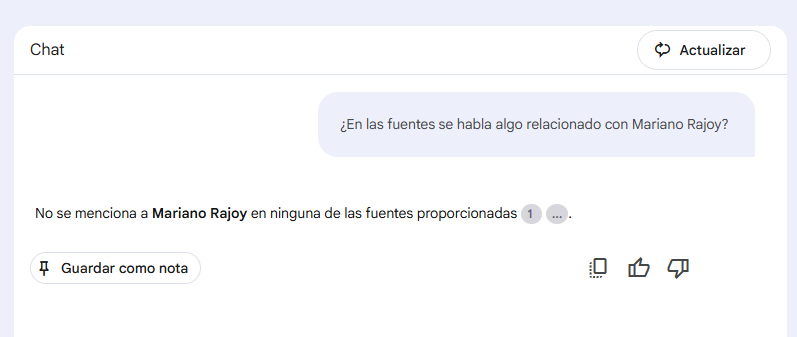
Y efectivamente (que yo recuerde), nunca he hablado de Mariano Rajoy con ChatGPT.
También podemos jugar un poco y pedirle que, con todo lo que sabe, describa nuestros gustos. La respuesta es una pasada:

Ha sacado cosas de muchos recovecos, e incluso ha recordado las indicaciones que le di a ChatGPT en el modo "Deep Research" para generar una guía de viaje para Bristol, con "arquitectura bonita, miradores, calles comerciales y gastronomía local". Increíble.
Esto nos puede servir para generar perfiles profesionales, escribir nuestro CV o reenfocar nuestra profesión con una imagen a vuelo de pájaro.
También le he pedido que categorice los chats por temáticas, para saber de qué temas le suelo preguntar y dónde tengo más puntos débiles o lagunas de conocimiento. Incluso se pueden sacar mapas mentales de las temáticas los chats.

No quiero sobrecargar la lección con más capturas. Cada uno puede investigar y hacer pruebas según sus necesidades. Te dejo una lista de otras preguntas que podrías hacerle a tu archivo de chats:
A partir de todas las fuentes, dime 10 proyectos interesantes con potencial de mercado que encajen en mi perfil.
Detecta temas que puedan convertirse en entradas para el blog Artificialmente (por desgracia, no me ha dicho ninguna buena, me toca seguir pensando…).
Lista todos los libros/películas que se citan o mencionan en las conversaciones (y recomiéndame otros nuevos a partir de esos).
Resume mis cinco áreas de conocimiento más sólidas basándote en todo el histórico.
Extrae todas las correcciones de inglés que me has hecho y agrúpalas por tipo de error.
Agrupa mis temas recurrentes en clústeres y muestra enlaces entre ellos.
Y la mejor de todas…
Dime en qué cosas suelo estar equivocado o tener una idea sesgada
Ideas finales
Las posibilidades que ofrece esto son muy interesantes. La idea es que la IA no solo sirva para generar contenido, sino también para retroalimentarse con esa información.
Este es el mayor problema que me encuentro a diario al usar ChatGPT o Gemini. No sirve de mucho que tengamos tanto contenido si no somos capaces de acceder a él y utilizarlo.
Los usuarios domésticos ya tenemos potencia de sobra para tareas cotidianas, pero nos falta organización para las fuentes de datos: que todo lo que generemos fuera a su vez fuente y que podamos incorporar todo lo que ya hay nuestro ordenador (libros completos, artículos, notas, informes, reflexiones...).
El siguiente paso natural es que todos los modelos integren o aumenten la memoria a largo plazo para ser ilimitada, y que lo que hemos hecho en esta lección sea una función básica.

PD: Aprovecho este correo para recordar que hemos abierto un grupo de Telegram para compartir herramientas, prompts y charlar un rato, exclusivo para suscriptores de la newsletter.
PD2: Si te están gustando las lecciones, dales un corazoncico, deja un comentario o comparte la newsletter con tus amigos y enemigos. Así me ayudas a conquistar el mundo llegar a más personas.
PD3: Solamente los pesados usan varias posdatas.
No lo he comentado porque habrá una lección dedicada a explorar NotebookLM, pero es necesario guardar cada respuesta como nota, ya que el chat se borra en cada visita.
No lo he probado pero los resultados son mucho mejores que hacer lo mismo en un GPT personalizado? Deduzco que sí pero donde crees exactamente? Mayor precisión? Menos alucinaciones?